Hadoop MapReduce
![]()
MapReduce Architecture
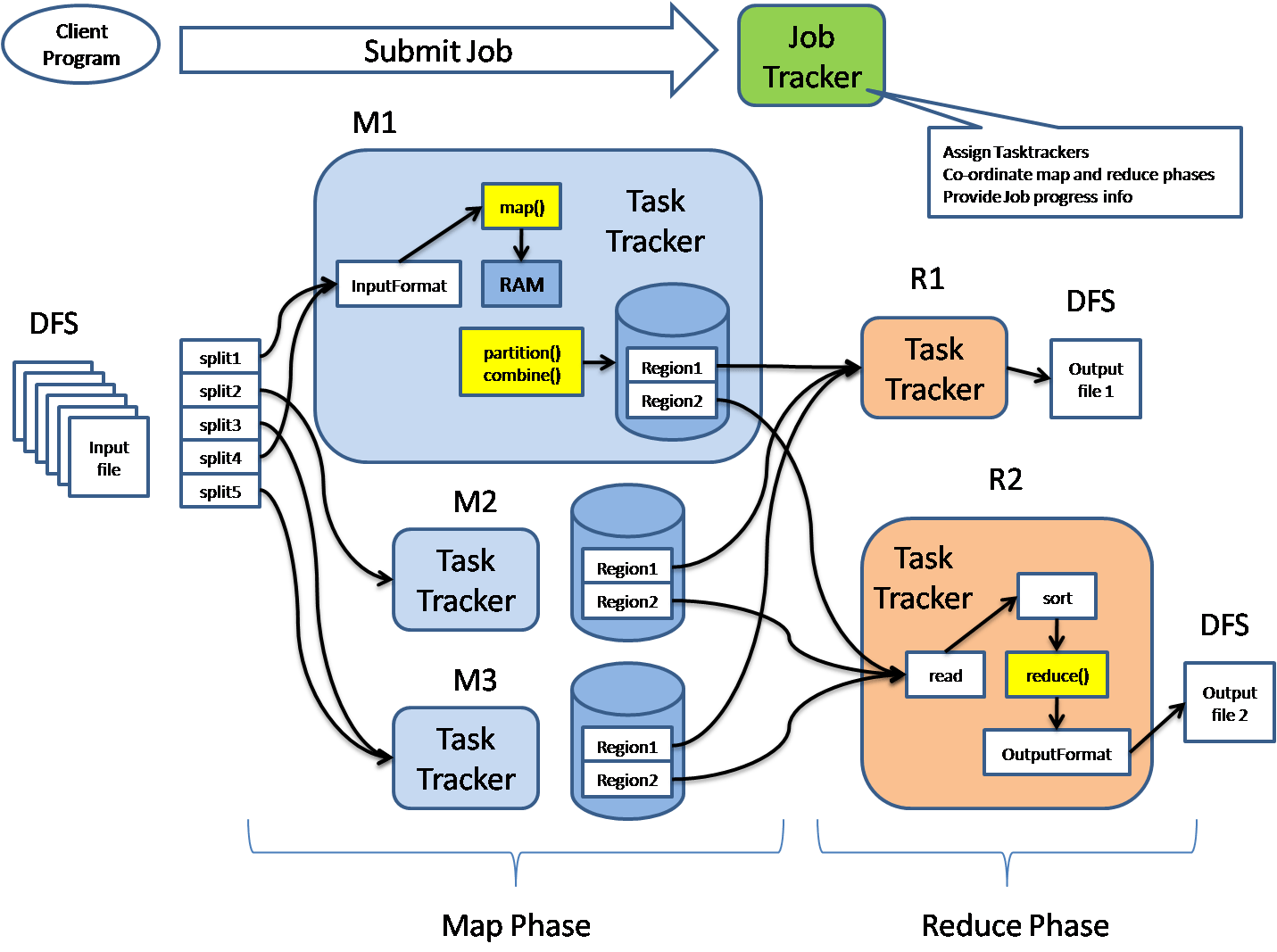
MapReduce architecture consists of various components. A brief description of these sections can enhance our understanding of how it works.
- Job: This is real work that needs to be done or processed
- Task: This is a piece of real work that needs to be done or processed. The MapReduce task covers many small tasks that need to be done.
- Job Tracker: This tracker plays a role in organizing tasks and tracking all tasks assigned to a task tracker.
- Task Tracker: This tracker plays the role of tracking activity and reporting activity status to the task tracker.
- Input data: This is used for processing in the mapping phase.
- Exit data: This is the result of mapping and mitigation.
- Client: This is a program or Application Programming Interface (API) that sends tasks to MapReduce. It can accept services from multiple clients.
- Hadoop MapReduce Master: This plays the role of dividing tasks into sections.
- Job Parts: These are small tasks that result in the division of the primary function.
In MapReduce architecture, clients submit tasks to MapReduce Master. This manager will then divide the work into smaller equal parts. The components of the function will be used for two main tasks in Map Reduce: mapping and subtraction.
The developer will write a concept that satisfies the organization’s or company’s needs. Input data will be categorized and mapped.
The central data will then be filtered and merged. The slider that will produce the last one stored on HDFS will process the output.

Hadoop Components
Namenode
The NameNode is the controller node responsible for receiving various tasks from the clients. The job of the primary node is to ensure that the data needed for the file operations are loaded in Hadoop and segregated into chunks of data segments. The main tasks of the primary node include:
- Management of the file system namespace
- Regulation of client’s access to files
There cannot be more than one NameNode server in an entire cluster. Hence, it acts as a core component of an HDFS cluster. It is responsible for various file systems namespace operations such as opening, closing, and renaming HDFS files and directories.
Secondary Namenode: People get confused with the name of a Secondary NameNode and treat it as a backup node. But the secondary node is not a backup node; instead, it is a helper node for the Namenode or a checkpoint node.
File System
HDFS follows the traditional hierarchical file system with directories and files and stores all the user data in the field format. Users can perform various operations on files like creating files, removing files, renaming files, copying or moving files from one place to another, etc. The NameNode allows the users to work with directories and files by keeping track of the file system namespace. The NameNode maintains the file system namespace and records the changes made to the metadata information.
Datanode
Datanode is also known as an agent node in HDFS. It is responsible for storing the actual data as per the instructions of the Namenode. More than one DataNode is available for a functional filesystem based on the type of network and the storage system, with data replicated across them. The Datanodes perform read-write operations on the Hadoop files per client request. It is also responsible for various functions like block creation, deletion, and replication, as instructed by Namenode.
The data block approach is helpful as it provides the following:
- Simplified data replication
- Fault-tolerance capability
- Reliability
Block
HDFS stores a vast amount of user data in the form of files. The files can further be divided into small segments or chunks. These segments are known as blocks, and they act as a physical representation of data and are used to store the minimum amount of data that can be written/read by the HDFS file system. By default, the size of a block is 64MB, which can be increased based on the need to change in HDFS configuration.
How do Job Trackers work?
Every task consists of two essential parts: mapping and reduction functions. Map work plays the role of splitting duties into task segments and central mapping data, and the reduction function plays the role of shuffling and reducing the central data into smaller units.
The activity tracker works like a master. It ensures that we do all the work. The activity tracker lists tasks posted by clients, and it will provide job trackers for jobs. Each task tracker has a map function and minimizes tasks. Activity trackers report the status of each task assigned to the task tracker. The following diagram summarizes how task trackers and task trackers work.
![]()
Phases of MapReduce
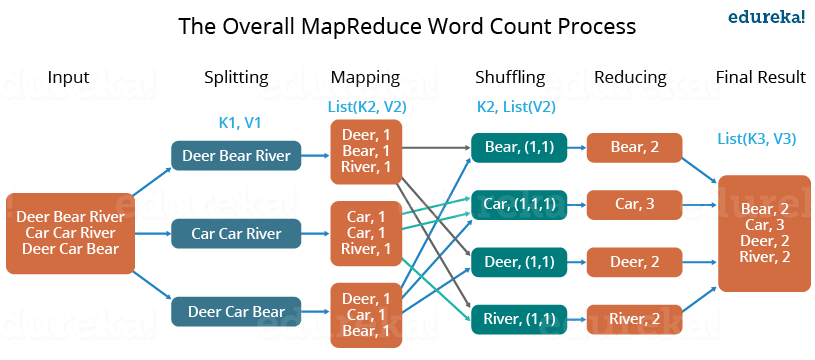
The MapReduce program comprises three main stages: mapping, navigation, and mitigation. There is also an optional category known as the merging phase.

Mapping Phase
This is the first phase of the program. There are two steps in this phase: classification and mapping. The database is divided into equal units called units (input divisions) in the division step. Hadoop contains a RecordReader that uses TextInputFormat to convert input variables into keyword pairs.
Key-value pairs are then used as input on the map step. This is the only data format a map editor can read or understand. The map step contains the logic of the code used in these data blocks. In this step, the map analyzes key pairs and generates an output of the same form (key-value pairs).
Shuffling Phase
This is the second phase that occurs after the completion of the Mapping phase. It consists of two main steps: filtering and merging. In the filter step, keywords are filtered using keys and combining ensures that key-value pairs are included.
The shoplifting phase facilitates the removal of duplicate values and the collection of values. Different values with the same keys are combined. The output of this category will be keys and values, as in the Map section.
Reducer Phase
In the reduction phase, the output of the push phase is user input. The subtractor continuously processes these inputs to reduce the median values into smaller ones. Provides a summary of the entire database. Output in this category is stored in HDFS.
The following diagram illustrates MapReduce with three main categories. Separation is usually included in the mapping phase.
Combiner Phase
This is the optional phase used to improve the MapReduce process. It is used to reduce pap output at the node level. At this stage, duplicate output from the map output can be merged into a single output. The integration phase accelerates the integration phase by improving the performance of tasks.
Benefits of Hadoop MapReduce
There are numerous benefits of MapReduce; some of them are listed below.
1. Highly scalable
A framework with excellent scalability is Apache Hadoop MapReduce. This is because of its capacity for distributing and storing large amounts of data across numerous servers. These servers can all run simultaneously and are all reasonably priced.
By adding servers to the cluster, we can simply grow the amount of storage and computing power. We may improve the capacity of nodes or add any number of nodes (horizontal scalability) to attain high computing power. Organizations may execute applications from massive sets of nodes, potentially using thousands of terabytes of data, thanks to Hadoop MapReduce programming.
2. Versatile
Businesses can use MapReduce programming to access new data sources. It makes it possible for companies to work with many forms of data. Enterprises can access both organized and unstructured data with this method and acquire valuable insights from the various data sources.
Since Hadoop is an open-source project, its source code is freely accessible for review, alterations, and analyses. This enables businesses to alter the code to meet their specific needs. The MapReduce framework supports data from sources including email, social media, and clickstreams in different languages.
3. Secure
The MapReduce programming model uses the HBase and HDFS security approaches, and only authenticated users are permitted to view and manipulate the data. HDFS uses a replication technique in Hadoop 2 to provide fault tolerance. Depending on the replication factor, it makes a clone of each block on the various machines. One can therefore access data from the other devices that house a replica of the same data if any machine in a cluster goes down. Erasure coding has taken the role of this replication technique in Hadoop 3. Erasure coding delivers the same level of fault tolerance with less area. The storage overhead with erasure coding is less than 50%.
4. Affordability
With the help of the MapReduce programming framework and Hadoop’s scalable design, big data volumes may be stored and processed very affordably. Such a system is particularly cost-effective and highly scalable, making it ideal for business models that must store data that is constantly expanding to meet the demands of the present.
In terms of scalability, processing data with older, conventional relational database management systems was not as simple as it is with the Hadoop system. In these situations, the company had to minimize the data and execute classification based on presumptions about how specific data could be relevant to the organization, hence deleting the raw data. The MapReduce programming model in the Hadoop scale-out architecture helps in this situation.
5. Fast-paced
The Hadoop Distributed File System, a distributed storage technique used by MapReduce, is a mapping system for finding data in a cluster. The data processing technologies, such as MapReduce programming, are typically placed on the same servers that enable quicker data processing.
Thanks to Hadoop’s distributed data storage, users may process data in a distributed manner across a cluster of nodes. As a result, it gives the Hadoop architecture the capacity to process data exceptionally quickly. Hadoop MapReduce can process unstructured or semi-structured data in high numbers in a shorter time.
6. Based on a simple programming model
Hadoop MapReduce is built on a straightforward programming model and is one of the technology’s many noteworthy features. This enables programmers to create MapReduce applications that can handle tasks quickly and effectively. Java is a very well-liked and simple-to-learn programming language used to develop the MapReduce programming model.
Java programming is simple to learn, and anyone can create a data processing model that works for their company. Hadoop is straightforward to utilize because customers don’t need to worry about computing distribution. The framework itself does the processing.
7. Parallel processing-compatible
The parallel processing involved in MapReduce programming is one of its key components. The tasks are divided in the programming paradigm to enable the simultaneous execution of independent activities. As a result, the program runs faster because of the parallel processing, which makes it simpler for the processes to handle each job. Multiple processors can carry out these broken-down tasks thanks to parallel processing. Consequently, the entire software runs faster.
8. Reliable
The same set of data is transferred to some other nodes in a cluster each time a collection of information is sent to a single node. Therefore, even if one node fails, backup copies are always available on other nodes that may still be retrieved whenever necessary. This ensures high data availability.
The framework offers a way to guarantee data trustworthiness through the use of Block Scanner, Volume Scanner, Disk Checker, and Directory Scanner modules. Your data is safely saved in the cluster and is accessible from another machine that has a copy of the data if your device fails or the data becomes corrupt.
9. Highly available
Hadoop’s fault tolerance feature ensures that even if one of the DataNodes fails, the user may still access the data from other DataNodes that have copies of it. Moreover, the high accessibility Hadoop cluster comprises two or more active and passive NameNodes running on hot standby. The active NameNode is the active node. A passive node is a backup node that applies changes made in active NameNode’s edit logs to its namespace.